こんばんは、松本山雅FCサポのすぴっちと言います。
先日、こんな記事を投稿しました。
その記事内の、下記の内容の解説になります。
> pythonで色々プログラム組んで試してみたのですが・・・丁度良い勉強となりました笑(その話は別の記事で)
1.課題
上述の記事の内容を実現するために、2点の課題がありました。
課題1. 大量の画像データ(分析対象選手の"攻撃スタッツ", "守備スタッツ")を取得する必要がある
課題2. スタッツは画像データ内のみ
もちろんどちらも”手動”でも実現可能。
しかし、、、
・合計524枚の画像データを手動で保存(ページ移動→右クリックして保存を繰り返す
・画像データを目視で確認し、エクセルに入力
、、、することは非常に面倒。
こういう面倒なことは”python”にやっていただこう。
2.課題1の解決:WEBページから画像データのURLを自動取得する
大まかな流れ:
使用させていただくのは、対象選手における各試合の個人スタッツが表示されるページ。
以下の図のような流れで、各スタッツ画像のURLを取得&画像をPCに保存する
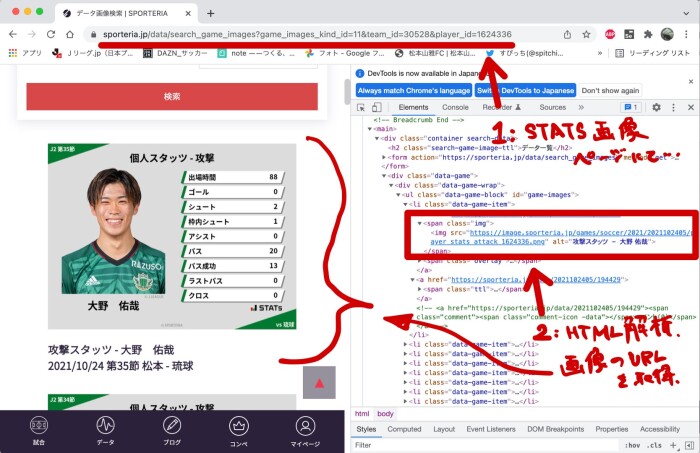
*WEBスクレイピング用のライブラリを使用(beautifulsoup)
*[注意]SPORTERIA様のサーバーに負荷がかからないように、短時間で連続で保存しないこと!!!
作成したコード:
https://github.com/spitchi-k/yamaga_python_test/blob/main/web_test.py
実行結果:
対象ページにおける全画像が、PCに保存される
3.課題2の解決:"文字認識"で画像データから数値を抽出
大まかな流れ:
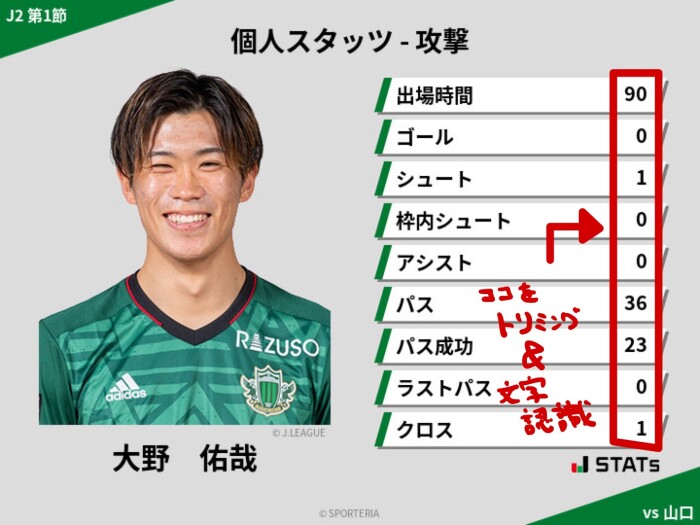
スタッツの画像データを使います。
1. 数値の部分をトリミング(= 切り抜き)
2. 文字認識の精度向上のため、色々と画像処理
→ グレースケール化 & 2値化したら、比較的上手くいった
3. OCR用のライブラリ(pyocr)を使用して、文字認識
作成したコード:
https://github.com/spitchi-k/yamaga_python_test/blob/main/ocr_test.py
実行結果:
対象画像の数値が、出力される
→ これを繰り返せば、数百枚の画像データから数値だけを抜き出せる
・・・という流れで、課題1,2を解決しました。
あとは集めた数値を色々計算すれば、完成。
4.終わりに
今回は "攻撃スタッツ"と"守備スタッツ"のデータを抽出して分析に使用させていただきました。
”ヒートマップ”の平均値も取れたら面白そうだなぁと思っており、アイディアを暖めております。





コメント(3)
-
 SPORTERIAスタッフ
2022/1/9 22:07
おおー、なるほど!
SPORTERIAスタッフ
2022/1/9 22:07
おおー、なるほど!
-
 SPORTERIAスタッフ
2022/1/9 22:10
P.S.
SPORTERIAスタッフ
2022/1/9 22:10
P.S.
-
 すぴっち
2022/1/10 08:24
>スタッツの合計÷出場時間の合計×90
すぴっち
2022/1/10 08:24
>スタッツの合計÷出場時間の合計×90
そのように収集&集計されていたのですね💡
pyocrで数値を認識していたとは👏
スタッツの合計÷出場時間の合計×90
で出しているのかと思っていたのですが、先に15分未満の試合を除外されていたのですね。
たしかに15分以内だと試合状況が特殊な確率も高いので、ありだと思います!
大変興味深く読ませていただきました!
こういうアナリティクス大好きなので、勝手ながらまた期待しています✨
データ検索ページは最近ひっそりとオープンして、まだ細かいところは手を入れないといけないのですが、早速このように使っていただけて嬉しいです☺
データのスクレイピング&ローカルでの集計も、このサイト内で再利用していただく分には全く問題ありませんので、使い倒して貰えればと思います(笑)
>で出しているのかと思っていたのですが、先に15分未満の試合を除外されていたのですね。
はい、「出場時間 1分、タックル数 1」 とかもあり、それを×90したマズイと思い除外しました
>データのスクレイピング&ローカルでの集計も、このサイト内で再利用していただく分には全く問題ありませんので、使い倒して貰えればと思います(笑)
このコメント・・・とてもありがたいです。
利用規約をよーく読んだのですが・・・大丈夫かなぁという不安もあったので(笑